PhD, Computer Science
Cornell University
I’m a Research Engineer at Fujitsu Research. You might know me from PyTorch Metric Learning, and A Metric Learning Reality Check.

I’m a Research Engineer at Fujitsu Research. You might know me from PyTorch Metric Learning, and A Metric Learning Reality Check.
Working on AI agents.
Analyzed and evaluated state-of-the-art machine learning research papers. Created engaging videos and informative blog posts to simplify the latest advances in AI for developers and executives. Represented HPE at leading machine learning conferences, demonstrated HPE products, generated sales leads, and increased awareness of HPE’s AI software offerings. Co-developed an interactive AI hologram simulation of HPE CEO Antonio Neri, which was showcased prominently at the 2024 HPE Discover event in Las Vegas.
Compared metric-learning loss functions on a level playing field and discovered that the performance difference between old and new methods is smaller than prior research indicated. Proposed significant improvements to the evaluation protocol.
Developed a behavioral-planning system for a self-driving car simulator, using reinforcement-learning algorithms.
Analyzed state-of-the-art deep-learning algorithms relevant to the autonomous-driving domain. Summarized the key performance metrics and trade-offs between various algorithms.

I built this code library (which now has over 6000 GitHub stars) to simplify metric learning, a type of machine-learning algorithm used in applications like image retrieval and natural language processing. This library offers a unified interface for metric-learning losses, miners, and distance metrics. It includes code for measuring data-retrieval accuracy and for simplifying distributed training. It also includes an extensive test suite and thorough documentation.

I built this library for training and validating domain-adaptation models. Domain adaptation is a type of machine-learning algorithm that repurposes existing models to work in new domains. For this library, I designed a system of lazily-evaluated hooks for efficiently combining algorithms that have differing data requirements. The library also includes an extensive test suite.

This library contains tools I developed to facilitate experiment configuration, hyperparameter optimization, large-scale slurm-job launching, as well as data logging, visualization, and analysis.
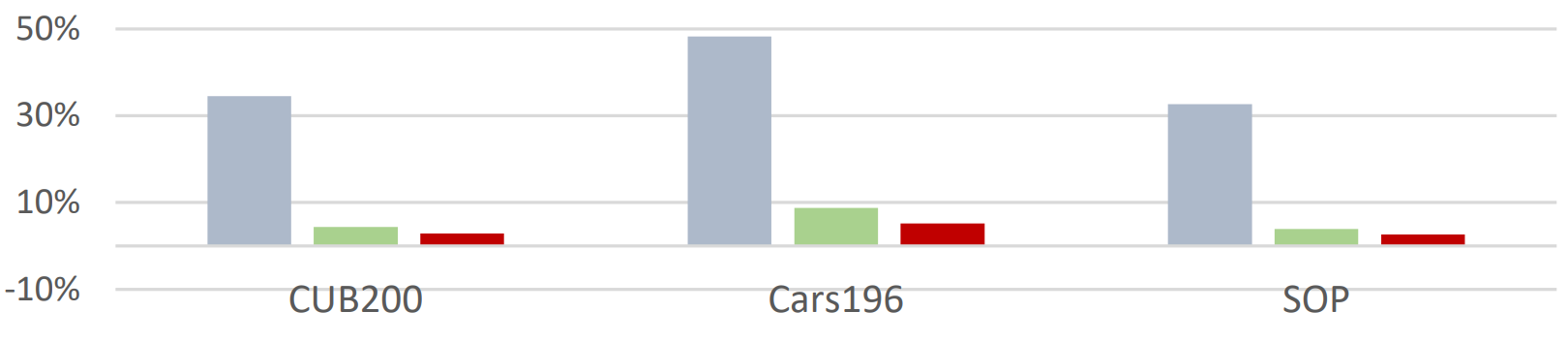
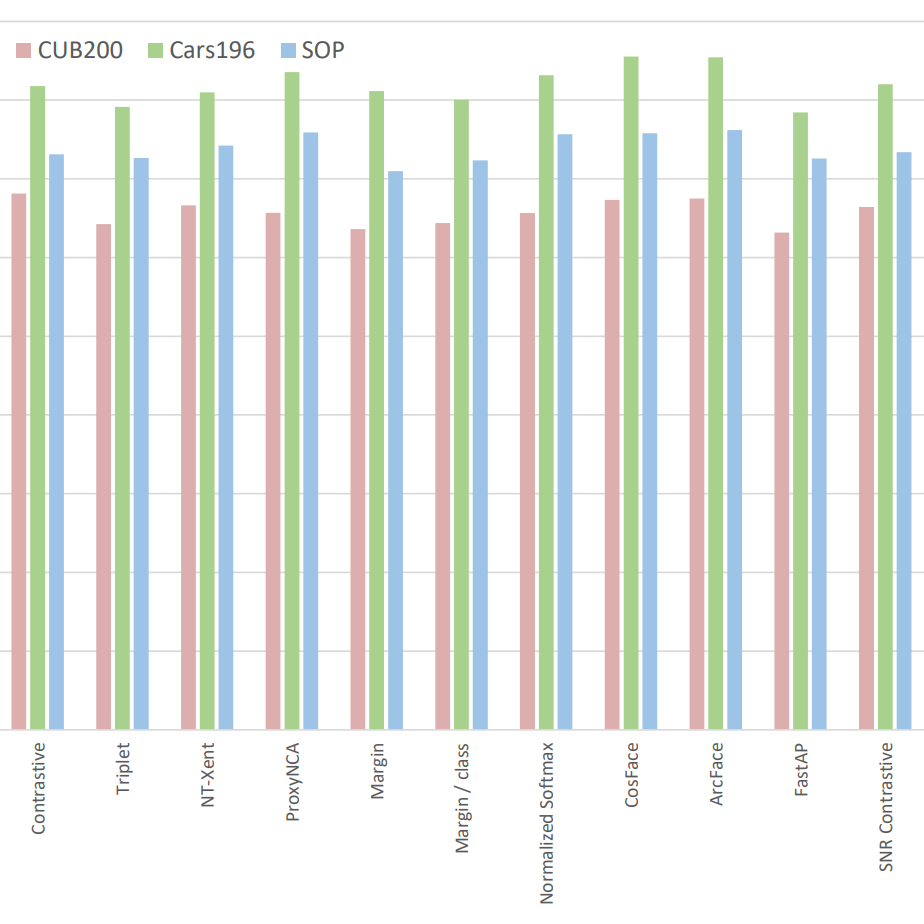
Many metric learning papers from 2016 to 2020 report great advances in accuracy, often more than doubling the performance of methods developed before 2010. However, when compared on a level playing field, the old and new methods actually perform quite similarly. We confirm this in our experiments, which benefit from significantly improved methodology.
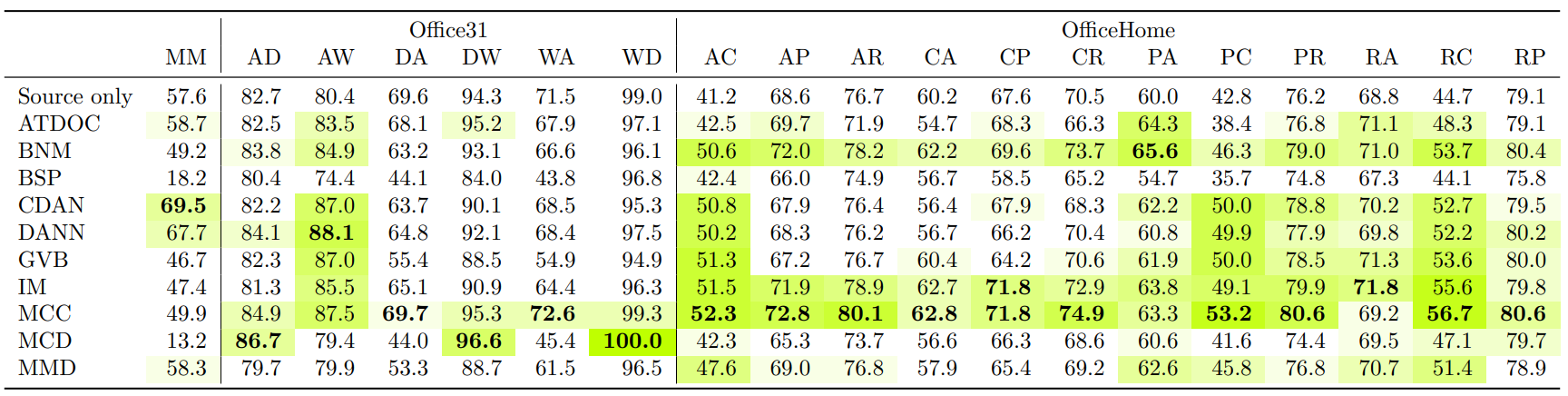
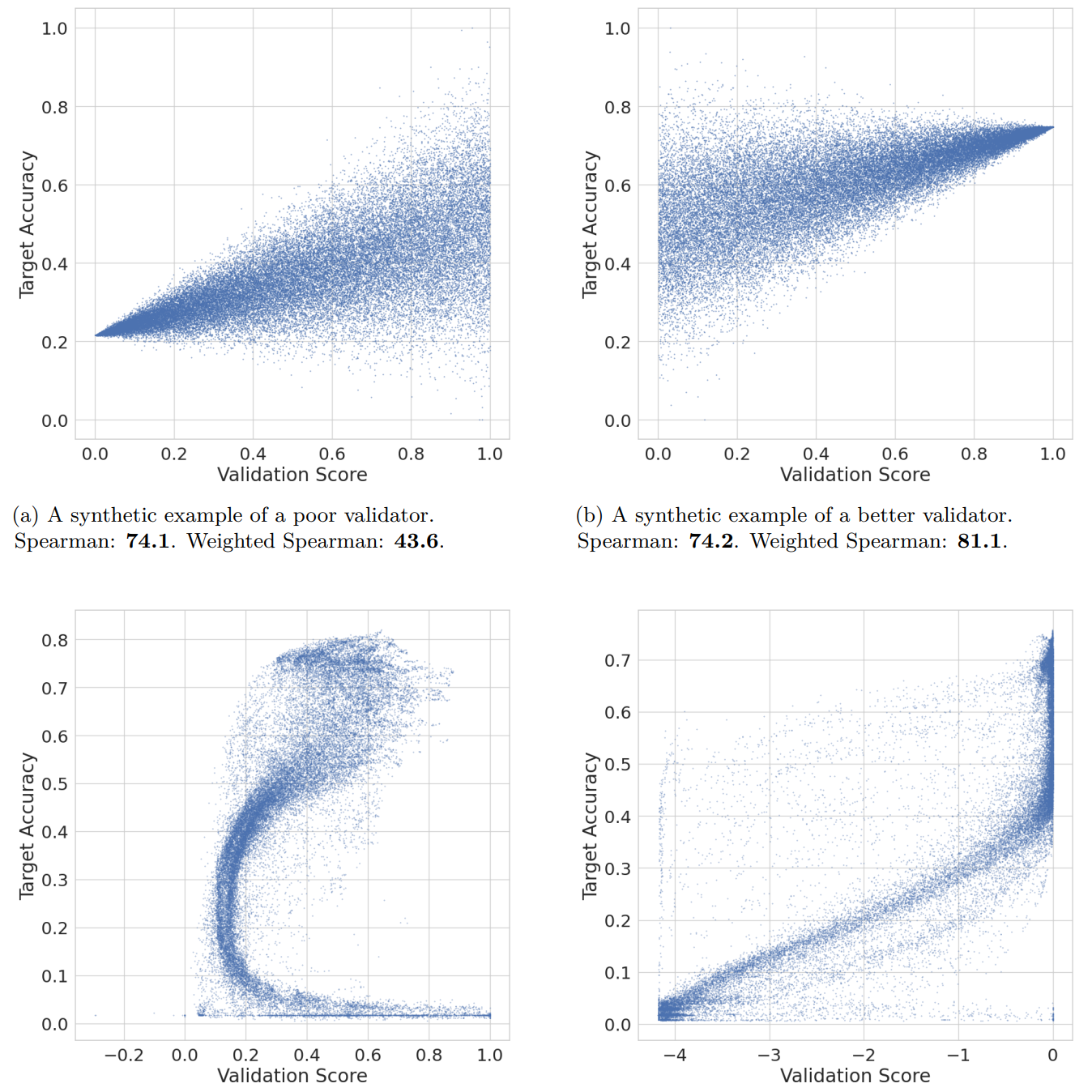
Unsupervised domain adaptation (UDA) is a promising machine-learning sub-field, but it is held back by one major problem: most UDA papers do not evaluate algorithms using true UDA validators, and this yields misleading results. To address this problem, we conduct the largest empirical study of UDA validators to date, and introduce three new validators, two of which achieve state-of-the-art performance in various settings. Surprisingly, our experiments also show that in many cases, the state-of-the-art is obtained by a simple baseline method.
Here is a video of me playing some Chopin.
And here is one of my own pieces.
See my music channel on YouTube for more.
Please use this form to contact me.
Site by Jeff Musgrave